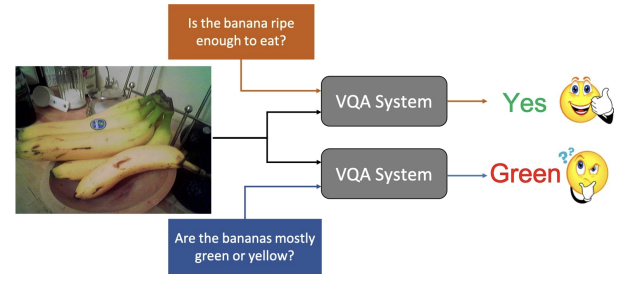
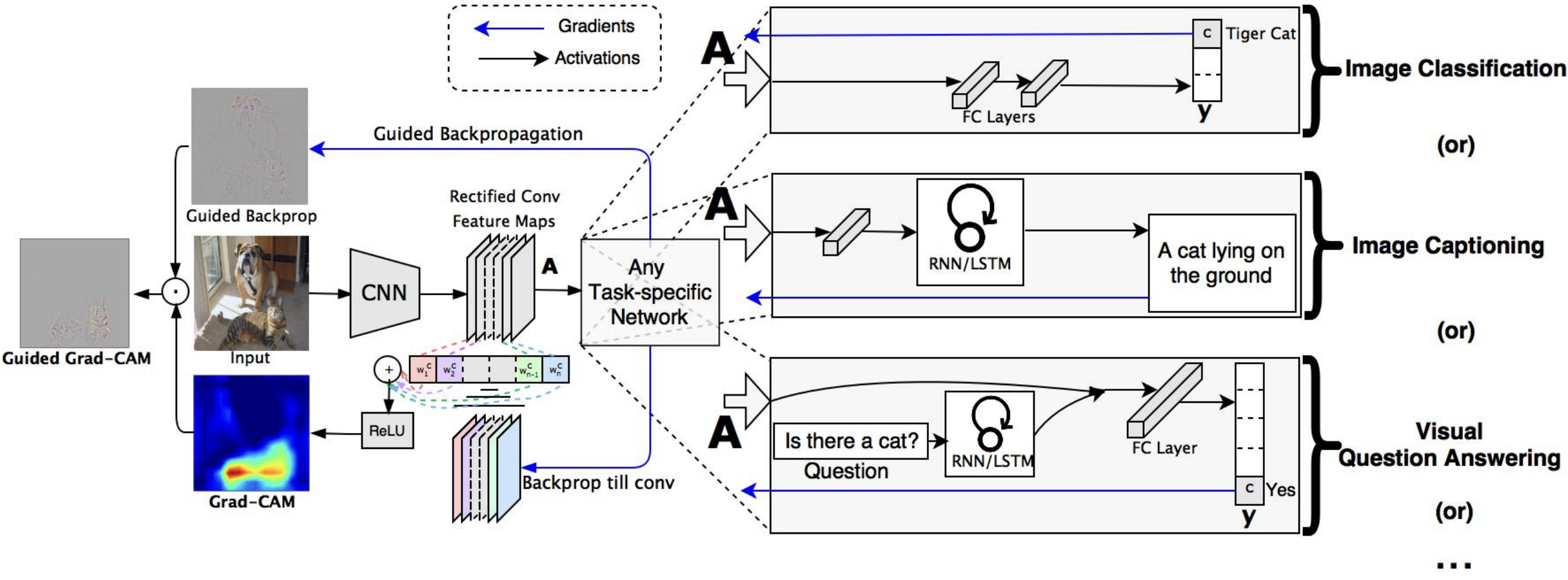
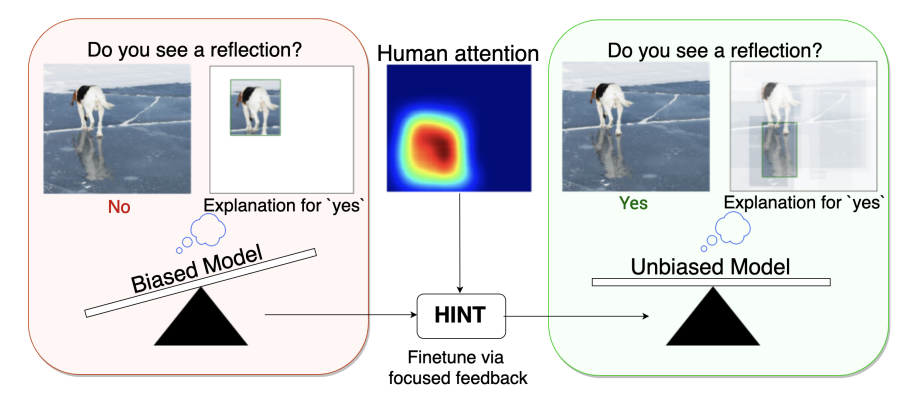
About Me:
Hello! I am a Senior Research Scientist at Apple, specializing in Computer Vision. I did my PhD at Georgia Tech advised by Prof. Devi Parikh and Prof. Dhruv Batra. My research focuses on advancing AI systems through —
- creating tailored solutions for enterprise applications while addressing model biases,
- understanding and interpreting model decisions while diagnosing failures,
- building trust and enabling knowledge transfer between humans and AI,
- encouraging human-like reasoning and grounded representations.
Check out my papers below and reach out to me if you would like to chat!
Education
-
Ph.D in Computer Science, 2020
Georgia Institute of Technology, Atlanta
Thesis: Explaining model decisions and fixing them via human feedback
-
Master of Science in Physics, 2015
Birla Institute of Technology and Science (BITS-Pilani), Hyderabad, India
-
Bachelor of Engineering in Electrical & Electronics Engineering, 2015
Birla Institute of Technology and Science (BITS-Pilani), Hyderabad, India
Awards & Recognition
-
2022
Recognized among the Top-100 scholars in the AMinor 2022 AI 2000 Most influential scholars in Computer Vision between 2012-2021.
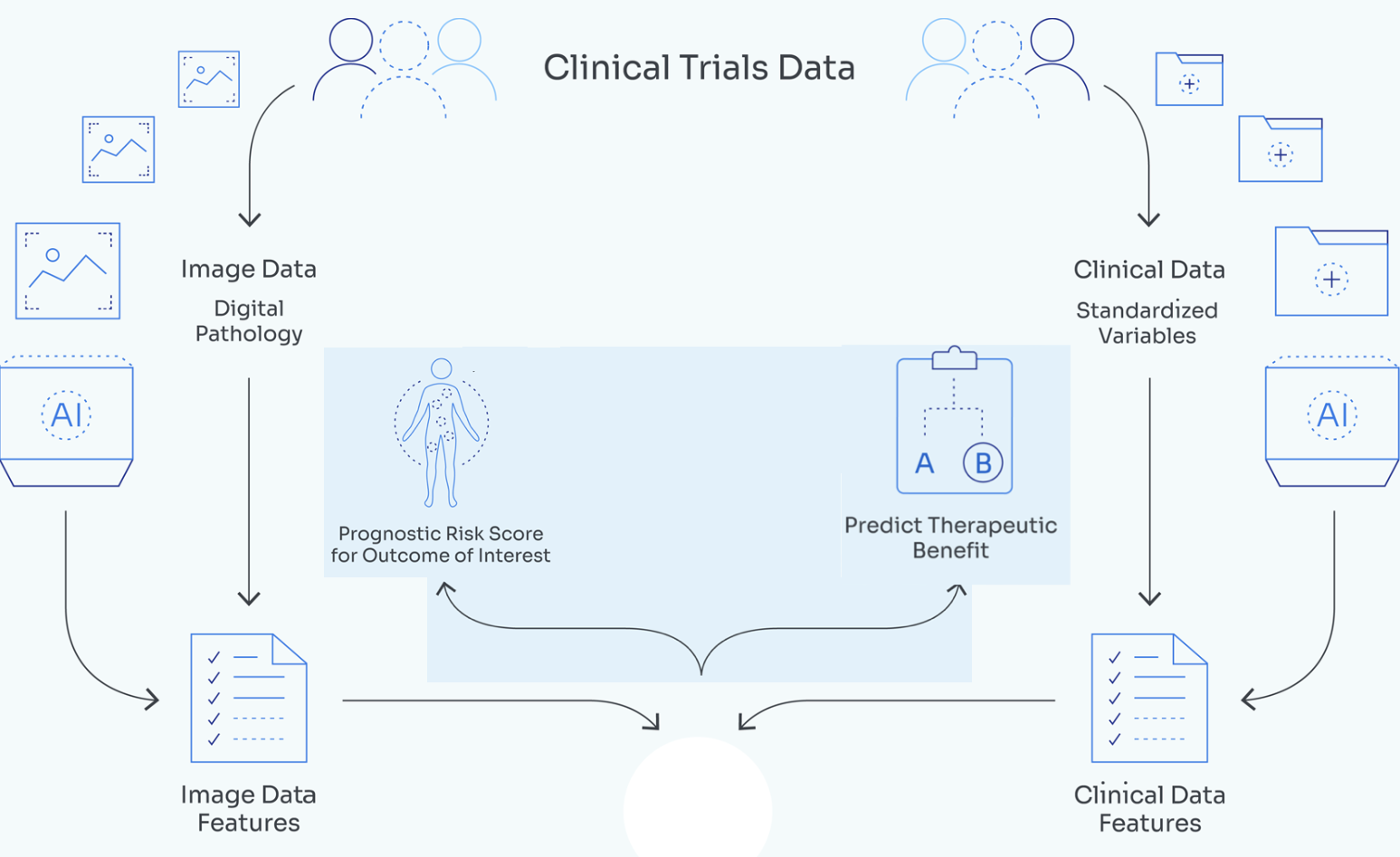
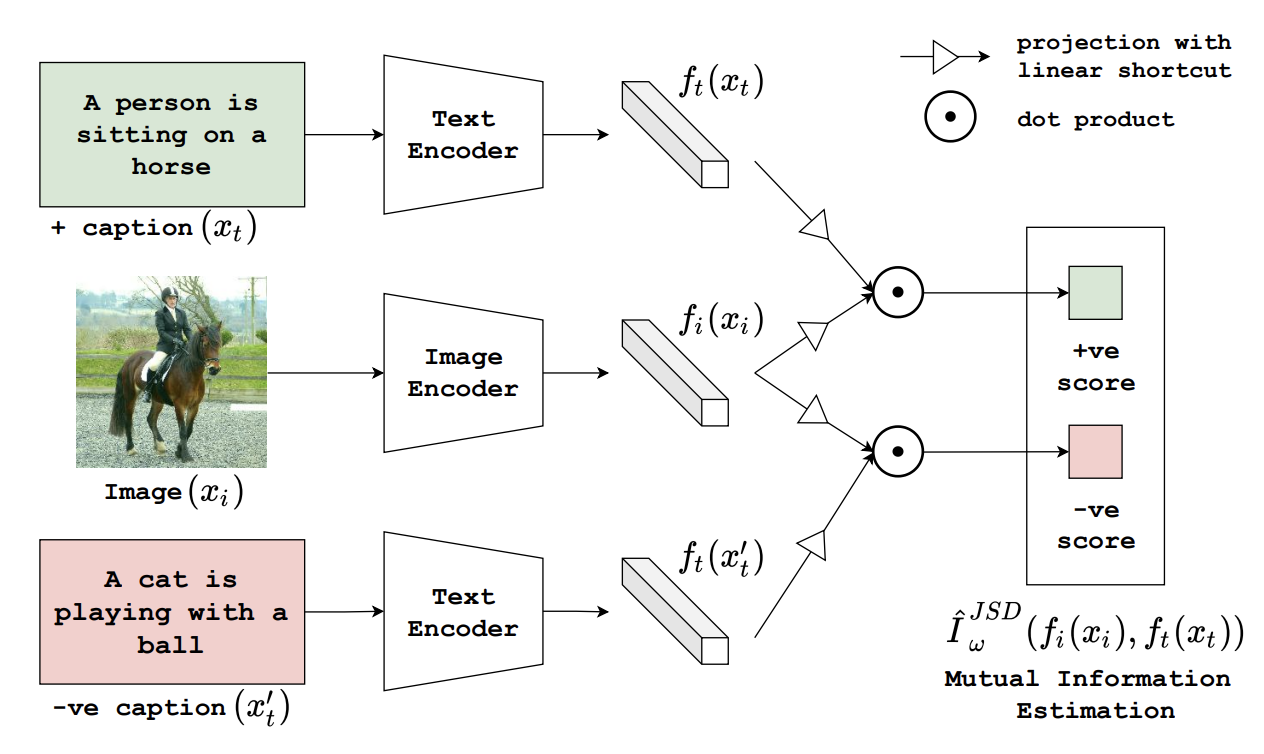
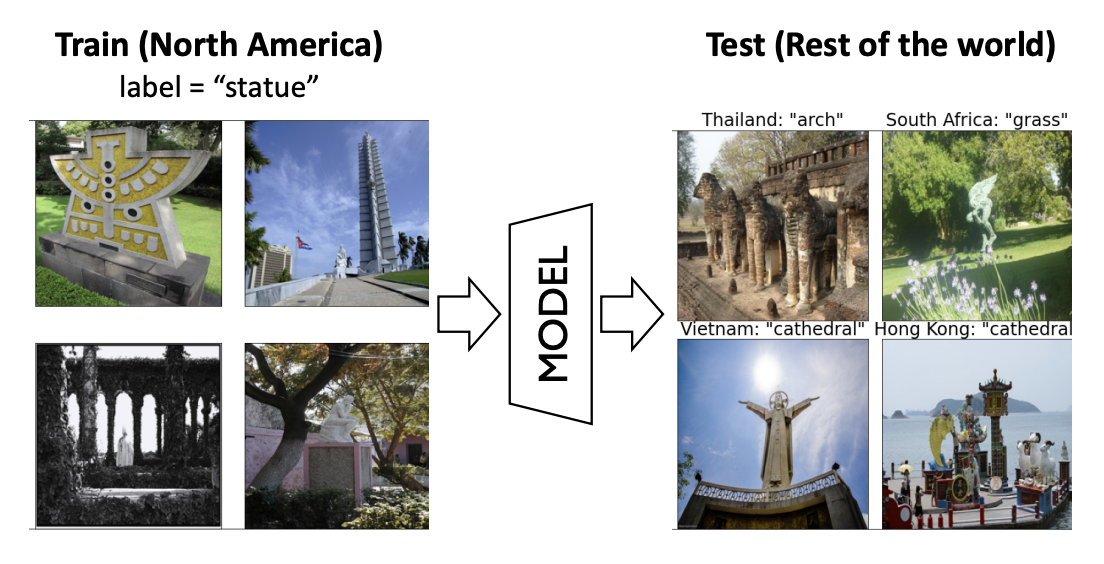
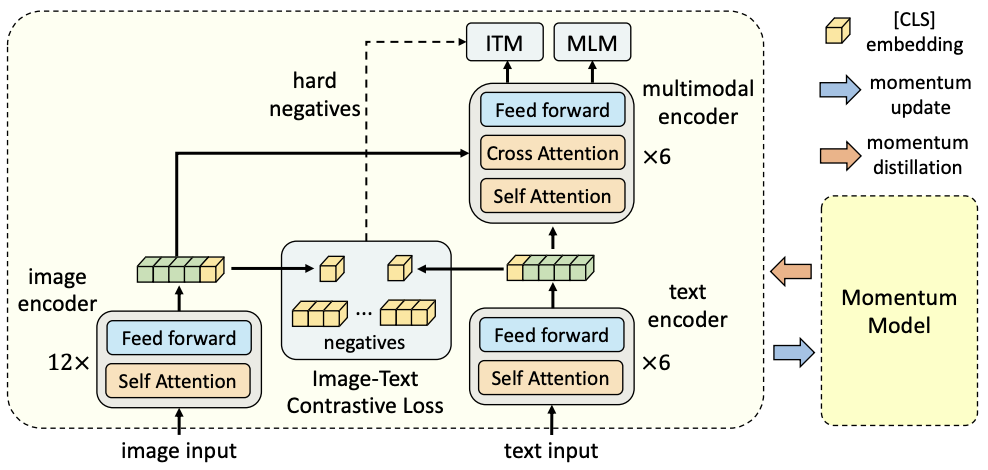
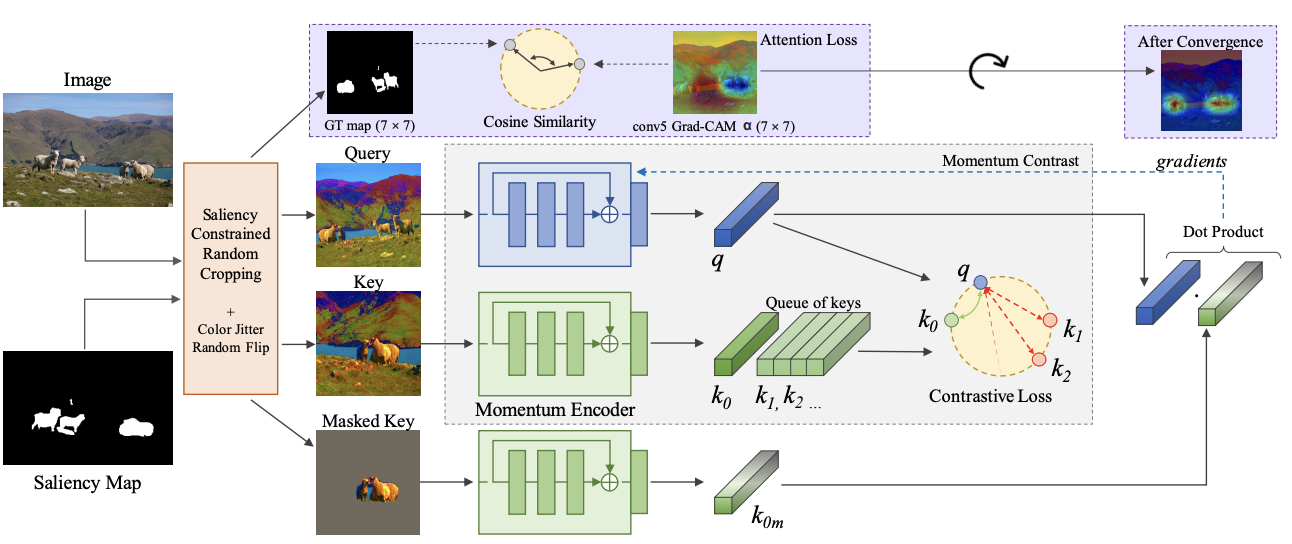
 Information efficient visual representation learning with language supervision
Information efficient visual representation learning with language supervision